Entrepôt de Données RH
ETL Pipeline · Star Schema · Talend · Postgresql · 2025–2026


📋 Contexte du Projet
Une entreprise souhaite centraliser les informations de ses employés afin d'améliorer la gestion des ressources humaines. Les données proviennent de trois sources hétérogènes (CSV, SQL et Excel) et doivent être intégrées dans un entrepôt de données unique selon une modélisation décisionnelle en schéma étoile.
Le projet couvre l'intégralité du cycle ETL : extraction multi-sources, nettoyage (doublons, valeurs nulles), jointures par identifiant employé, création de colonnes calculées (salaire annuel, total absences, nb formations), et chargement dans un DW structuré avec tables de faits et dimensions.
motif · duree_jours · justifie · remarque
───────────────────────
582 lignes · 62 doublons (10.7%)
Nulls : motif 9.3% · durée 8.6% · justifié 9.1%
86 employés concernés · 6 motifs distincts
salaire_mensuel · ville · email
───────────────────────
112 inserts employes → 100 uniques
12 doublons (nom en MAJUSCULES)
Nulls salaire: 14 · email: 9 · ville: 7
1 200 lignes salaires (100 emp × 12 mois)
durée (h) · année · coût (DT) · statut
───────────────────────
266 lignes · 28 doublons (10.5%)
Nulls : coût 11.7% · statut 11.3% · durée 9%
16 intitulés · années 2022–2024
tReplaceList → correction NULLs
Valeurs par défaut : "N/A", 0
tMap : employes ↔ formations
Clé de jointure : matricule
Total jours d'absence / employé
Nombre formations / employé
sk_employe · sk_temps
sk_formation · sk_absence
FK sk_temps · FK sk_absence
FK sk_formation
salaire_mensuel · salaire_annuel
nb_jours_absence · nb_formations · prime
→ 1 032 lignes chargées
prénom · service · ville · email
→ 100 lignes
jour · mois · trimestre · année
nom_mois · nom_jour · est_weekend
→ 1 096 lignes (2022–2024)
date_absence · motif · duree_jours · justifié
→ 520 lignes
intitulé · durée · année · coût · statut
→ 238 lignes
🗄️ employes_salaires.sql
📄 absences_presences.csv
📊 formations.xlsx
Job_InitialLoad — Chargement des tables staging
Sources → rh_entreprise : DDL + chargement des 4 tables de staging
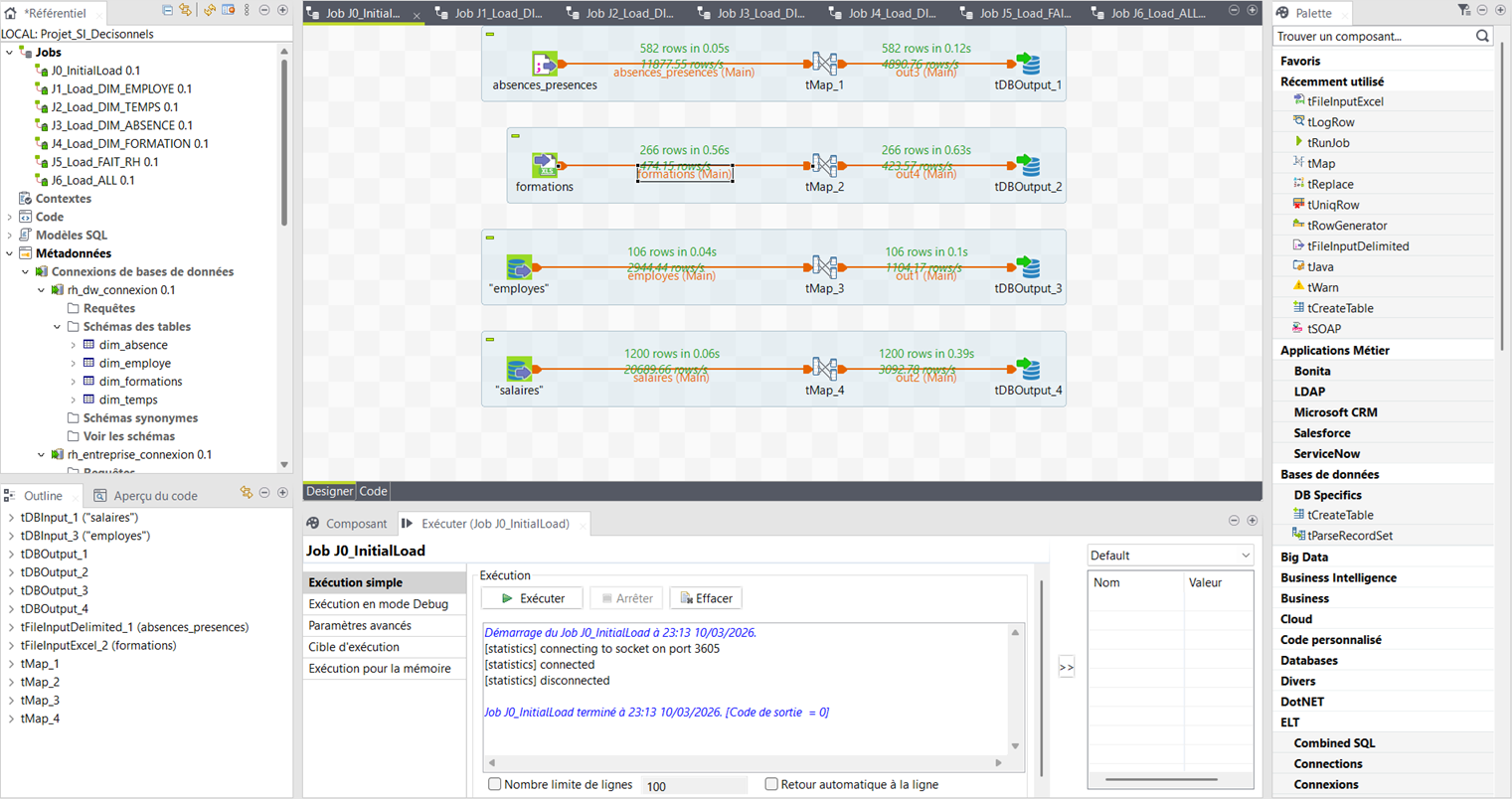
Job_Load_DIM_EMPLOYE
stg_salaires (1200) + stg_employes (106) → DIM_EMPLOYE (100 lignes)
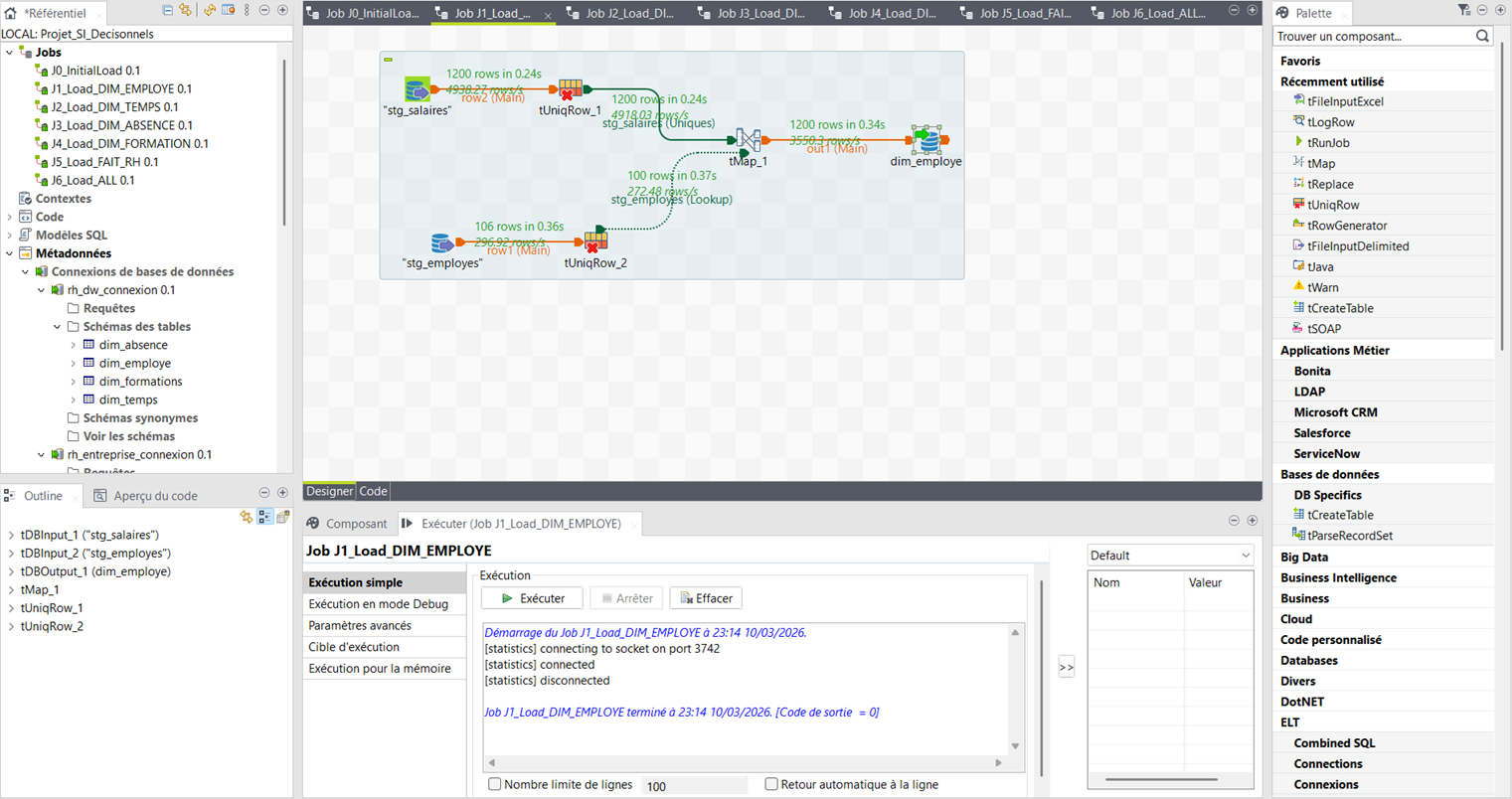
Job_Load_DIM_TEMPS
Génération programmatique → DIM_TEMPS (1 096 lignes)
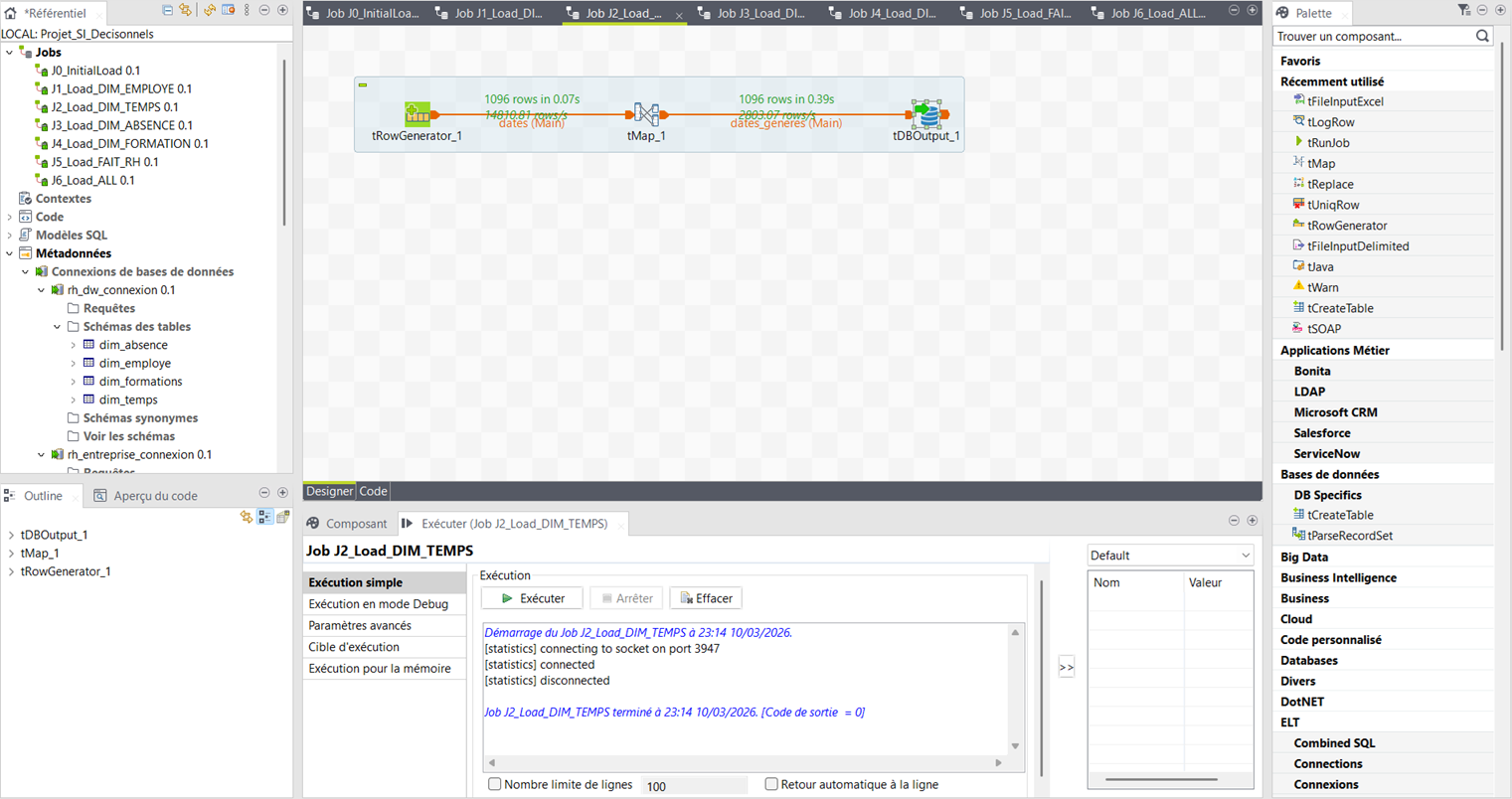
Job_Load_DIM_ABSENCE
stg_absences_presences (582) → DIM_ABSENCE (520 lignes)
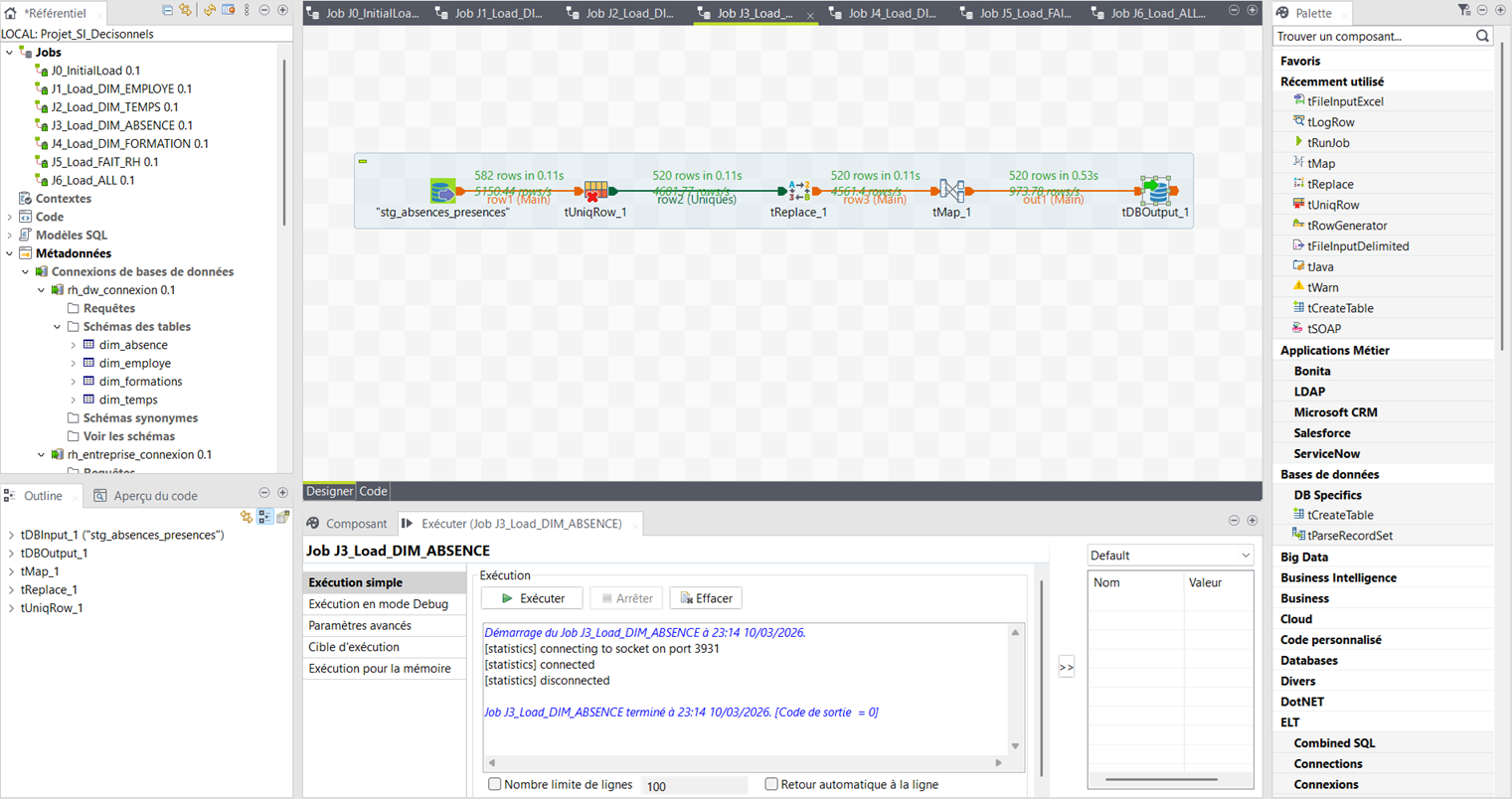
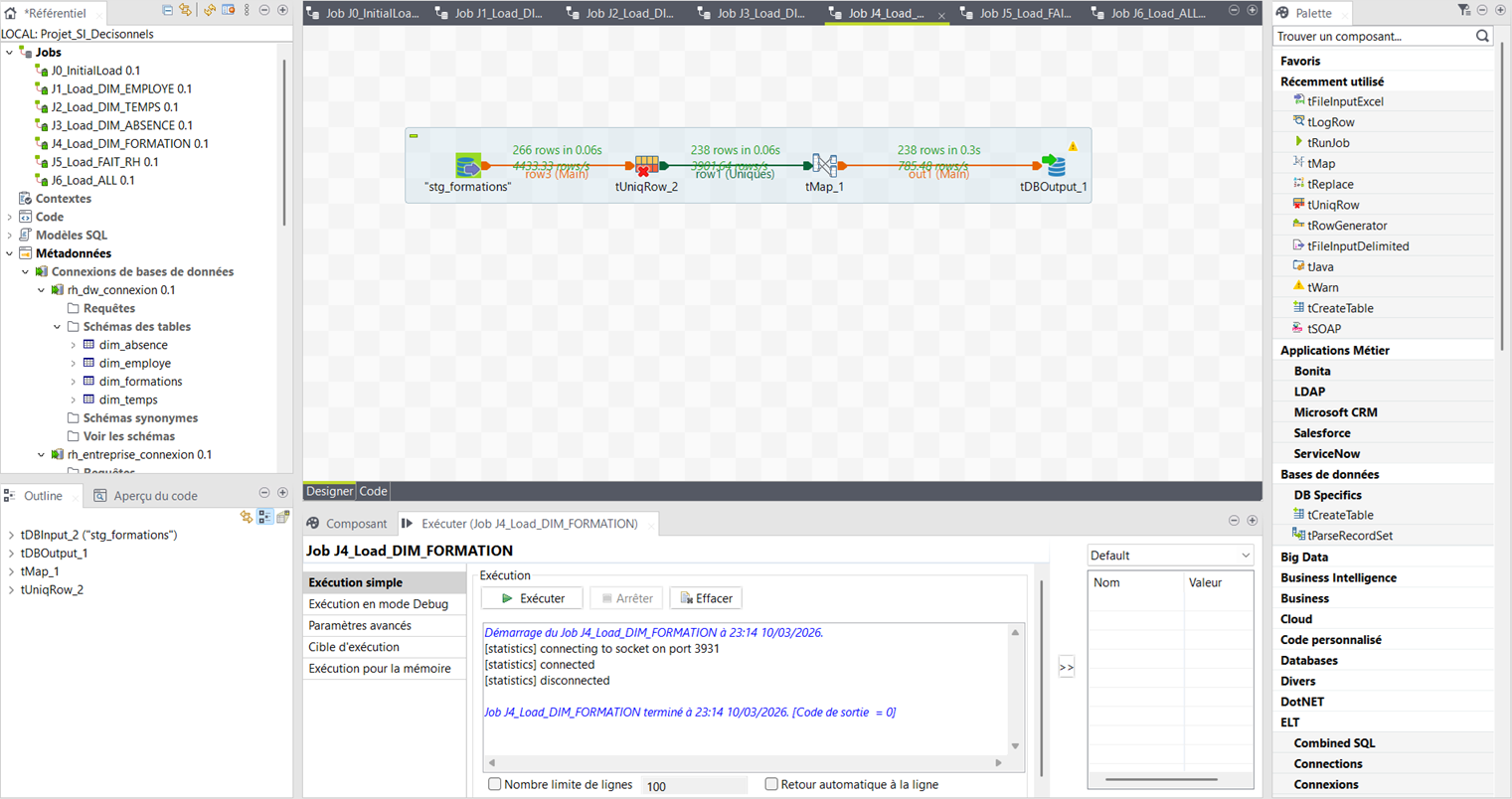
Job_Load_DIM_FORMATION
stg_formations (266) → DIM_FORMATION (238 lignes)
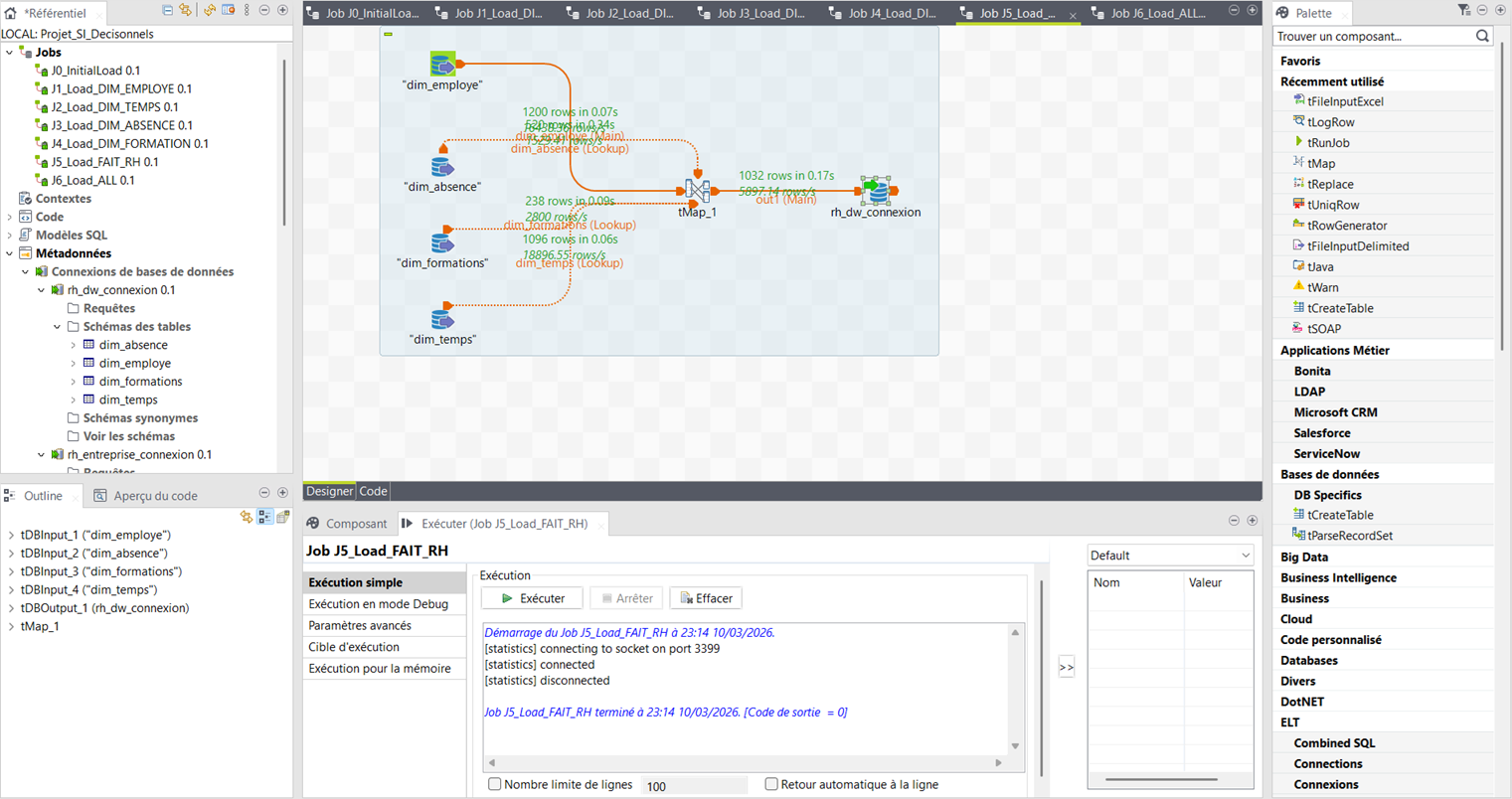
Job_Load_FAIT_RH — Table de Faits (exécuter en dernier)
dim_employe + lookups absences/formations/temps → FAIT_RH (1 032 lignes)
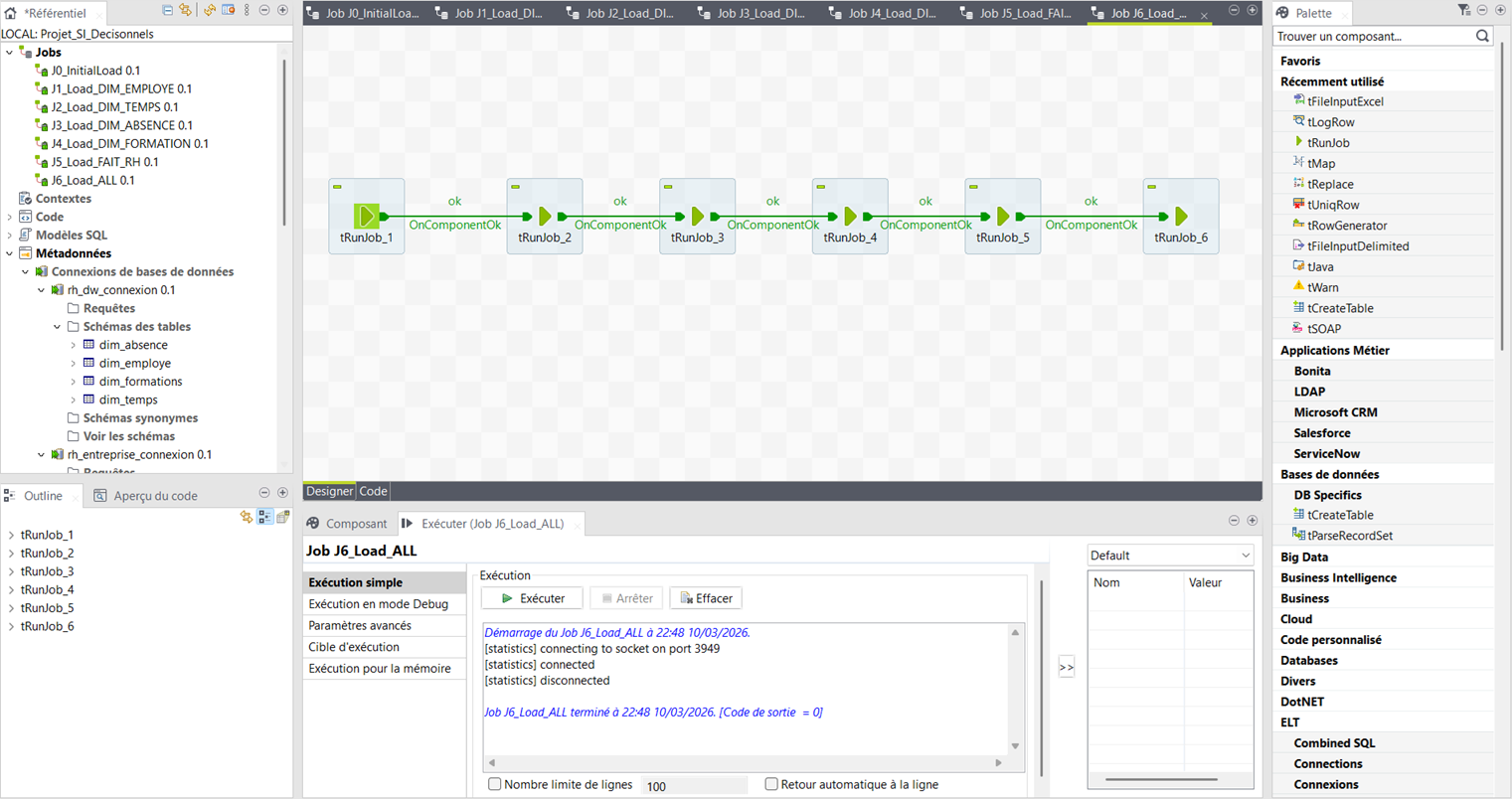
Job_Load_ALL — Orchestrateur complet
Chaîne les 6 jobs J0 → J5 en séquence avec OnSubjobOk


🛠️ Paramètres de Génération
📦 Résultat de Génération
Durée totale ≈ 03 min et 09 secondes · Résolution 1080p